Hexes! If you like boardgames you probably love those awesome maps were terrain has been transformed into a grid of hexagons (popularly known as hexes). Beyond this geeky interest hex-based maps can be used to create interesting visualizations where you want to colour the map based on a specific variable.
These visualizations are technically known as choropleth maps and they divide the space into a set of polygons that could be anything: country boundaries, Voronoi diagrams or regular tiles.
Regular tiles are interesting if you don’t have a relevant distribution of pre-existing polygons. But what type of tile would you use? The typical approach is to use a grid of squares but as boardgamers already know this is far from perfect. The issue here is that the distance between a square centre and its neighbours depends on their configuration: it will be larger for the ones in the corners than the ones at right/left/top/bottom as Pythagoras knew some centuries ago. Hexagons better capture the spatial relation between tiles because the 6 neighbors of each hexagon are roughly positioned at the same distance of its centre. Also, did I mention that hexmaps look awesome?
Ok, let’s see how can we create an hexagon-based map with QGIS.
Roman camps in Scotland
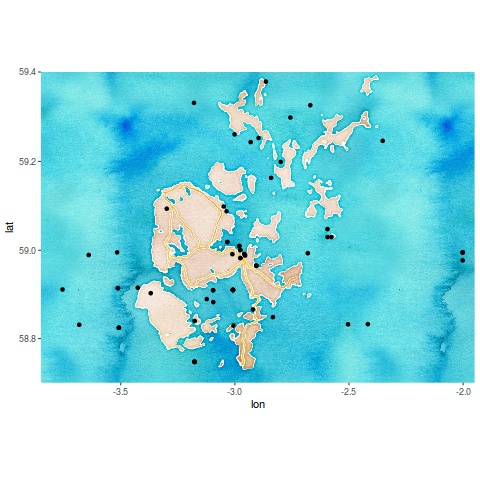
We know that the Romans legions adventured beyond the Antonine wall; the sources talk about military campaigns and archaeological evidence support this idea because several temporary march camps have been found in Scotland. But where do we find these camps? To answer this question let’s create an hexmap where the hexes are coloured based on the number of temporary camps in the region.
Load the dataset
This zip file contains 2 vector files in Shapefile format:
– scotland_boundaries.shp has the boundaries of the region
– roman_camps.shp is the set of identified Roman temporary camps compiled by Canmore.

Install the mmqgis plugin
Go to Plugins -> Manage and Install Plugins and install mmqgis. This plugin extends the functionality of QGIS for vector map layers.

Create an hexagonal grid
Once mmqgis is enabled you can use its functionality to create the hexes; go to MMQGIS -> Create -> Create Grid Layer and select Hexagons as the layer type.
You should set as extent the layer scotland_boundaries because we want the grid to cover the entire region. You can finally define the size of the hexes; I chose here 25km because it is roughly the distance a legion can cover in a day.

Intersect the grid with the boundaries
You probably got an hexagonal grid covering a large rectangle; it is kind of useless because to my knowledge Romans did not have submarines, so we should remove from the grid everything that is not land. In essence we want to remove from the grid everything outside the scotland_boundaries layer. You can do this using the command Intersection from Vector -> Geoprocessing Tools.
You need to specify the hex grid as the Input layer and the boundaries as the Intersect Layer. Please be aware that this process will take a while, specially if you defined a small hex size.
Count the number of camps per hex
The last step is to create a new hexagonal layer with an attribute defining the number of camps per hex. This algorithm is not in the Menus so you should open the Toolbox inside the Processing menu. Go to QGIS -> Vector analysis tools and select Count points in polygon.

The input parameters for the algorithm are straightforward; fill them and create this new layer.

Visualize the result
Double-click on the new layer and set the type of Style to Graduated based on the attribute NUMPOINTS. Classify using a decent color ramp and you are done!


Discussion
You can use this method to overlap several layers of information:

What can we say from this visualization? Some interesting spatial patterns are clearly visible:
1. The Firth of Forth seems to concentrate the majority of camps
2. The Romans definitely did not like Western Scotland. They probably did not want to move far from the coast where their fleet supported them
3. The route followed by the armies was probably used as the basis for the Gask Ridge fortification line
Acknowledgements
This post was heavily inspired by the entry written by Anita Graser in her blog